Untitled 서비스에서는 회원가입시 '기본 유저 정보' 외에 '반려 동물' 정보, '관심사' 정보를 입력받아서 처리해준다.
회원가입을 구현하셨던, 개발을 꽤 잘하는 김 모 개발자님은(지금은 취뽀하셔서 함께 하지 못하신다.. 기쁘면서 슬프다) 회원가입 과정에서 반려동물 정보와 관심사 정보를 생성할 때 발생한 예외가 회원가입에 영향을 미쳐서 롤백된다면 유저 경험에 좋지 못하다고 생각을 하셨고, 과감하게 @Transactional을 빼버리셨다.
(@Transactional에서 Exception이 발생하면 roll-back only mark가 생기고, 예외 처리를 하더라도 이 트랜잭션은 재사용이 불가능하다. 왜 그런지는 다음 링크를 참고해보자! https://techblog.woowahan.com/2606/)
응? 이게 왜 롤백되는거지? | 우아한형제들 기술블로그
이 글은 얼마 전 에러로그 하나에 대한 호기심과 의문으로 시작해서 스프링의 트랜잭션 내에서 예외가 어떻게 처리되는지를 이해하기 위해 삽질을 해본 경험을 토대로 쓰여졌습니다. 스프링의
techblog.woowahan.com

하지만 db에 데이터를 넣는 메서드에서 @Transactional이 주는 장점인 원자성, 일관성, 독립성, 트랜잭션 관리 등을 포기 할 수는 없는 입장이어서 방법을 찾아보았다.
@Transactional(propagation = REQUIRES_NEW) 를 사용하여 자식 트랜잭션 예외가 부모 트랜잭션에 전파가 되지 않게 해보자
먼저 event로 처리하는 방법과 @Transactional의 전파 옵션을 사용하는 방법을 찾았다. 그런데 event는 도메인간 의존성을 분리하기 위해 사용하고 있었는데 회원가입에서 사용되는 메서드들은 모두 같은 도메인에 위치해있었고, 무엇보다도 @Transactional의 전파 옵션을 사용해보고 싶은 마음이 컸기에 REQUIRES_NEW를 사용해서 해결해보기로 했다.
**(REQUIRES_NEW를 사용할 때 동시에 실행되는 트랜잭션에서 DB 접근이 많이 있다면, 하나의 요청에서 여러 DB Conncetion을 점유하기 때문에 데드락을 조심해야 한다. 따라서 사용하지 않아도 된다면 그냥 사용 안하는게 좋지 않을까 싶다)
propagation = REQUIRES_NEW 란?
- @Transactional 어노테이션의 propagation 옵션중 하나
- REQUIRES_NEW가 선언된 메서드는, 새로운 트랜잭션에서 실행된다. 이전에 실행중이던 부모 트랜잭션이 있다면, 그 트랜잭션은 잠시 중단하고 새로운 자식 트랜잭션을 실행시킨다
- 아예 다른 트랜잭션이기에, 현재 트랜잭션의 결과가 부모 트랜잭션이나 다른 자식 트랜잭션에 영향을 미치지 않는다
코드

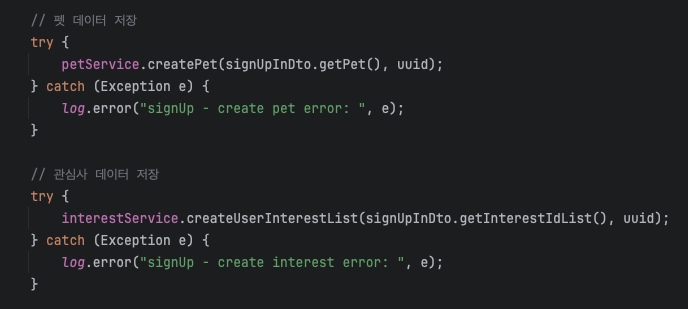
먼저 부모 트랜잭션의 코드이다. signUp 메서드는 @Transactional 어노테이션을 사용하고 있고, petService와 interestService에서 각각 Pet 생성과 Interest 생성 메서드를 호출하고 있다.
내가 원하는건 Pet 생성과 Interest 생성 메서드에서 발생한 예외가 signUp 메서드로 전파되지 않는 것이므로, 각각 메서드에 @Trasactional(propagation = Propagation.REQUIRES_NEW)를 걸어주자


각 메서드에서 REQUIRES_NEW 옵션을 사용하여 새로운 트랜잭션에서 실행되도록 코드를 수정했다.
여기서 주의할점은 '완전하게' 독립적이라고 표현하기는 힘들다는 것이다. 자바에서 예외 처리 메커니즘상, 예외가 발생하면 최초 호출 시점까지 예외가 전파가 된다. 따라서 만약 예외가 발생했을 때, 예외처리를 따로 해주지 않으면 여전히 자식 트랜잭션의 예외가 부모 트랜잭션까지 영향을 미치기 때문에 '완전한' 독립이라 말하기는 힘들다.
그렇다면 REQUIRES_NEW를 사용하지 않고 try-catch로 예외 처리만 해준다면 어떻게 될까?
정답은 부모 트랜잭션도 'roll-back'이 된다가 정답이다.
위에서 언급한 우아한기술블로그에서 잘 설명이 되어있겠지만, REQUIRES_NEW를 사용하지 않으면 동일한 물리 트랜잭션(DB 트랜잭션이라 생각하면 됨)을 사용하고, 이 물리 트랜잭션을 관리하는 'PlatformTransactionManager'는 동일한 물리 트랜잭션을 roll-back 시키므로 예외처리를 해주더라도 roll-back 처리가 된다.
따라서 예외 처리를 필수적으로 해주어야 한다.
예외 발생: 부모 트랜잭션에서 저장한 Entity가 자식 트랜잭션에서는 조회가 안된다?
그러나 첫 술에 배가 부를 수는 없는 법.. 역시나 예외가 발생하고 말았다
REQUIRES_NEW로 실행되는 자식 트랜잭션에서, 부모 트랜잭션에서 save한 entity가 자식 트랜잭션에서 조회가 되지 않는 것이다.

분명 로직 순서상 부모 트랜잭션에서 Users를 repository에 먼저 save하고 이후에 pet 생성 메서드를 실행했는데 어떻게 된 일일까?
원인을 파악하기 위해 JPA의 save와 find 메서드를 찾아보았다.
SpringDataJPA에서 save와 find 메서드의 동작 과정과, Transaction에 따른 persistence context로 예외 원인 찾아보기
1. save
save() 메서드의 동작 과정을 보면, save가 호출된 시점에 곧 바로 db에 저장되는 것이 아니라 트랜잭션에 영향을 받는다는 것을 알 수 있다.
- em.persist()
- em.commit(): Transactional wirte-behind에 의해, 트랜잭션을 커밋하기 직전까지 write-behind 저장소에 SQL을 모아두고, 트랜잭션이 커밋 되면 모아둔 쿼리를 한번에 DB로 보낸다
- em.flush()
여기서 persist는 영속성 컨텍스트(persistence context)의 1차 캐시에 데이터를 저장하는 것이고, flush는 영속성 컨텍스트에 저장된 데이터를 db에 영구저장하는 단계이다.
따라서 트랜잭션에서 커밋이 이루어져서 2. em.commit()이 호출되기 전까지는 db에 데이터가 영구 저장되지 않는다는 것이다
2. find
그러나 find() 메서드의 동작 과정을 보면, em.find()를 통해 영속성 컨텍스트의 1차 캐시에서 먼저 entity를 찾아보고, 없으면 이후에 db를 조회하는 방식으로 동작한다.
- em.find(): 영속성 컨텍스트에서 먼저 조회
- db에서 find: 영속성 컨텍스트에 entity가 없다면 db에서 조회
그렇다면 save가 호출된 시점에 트랜잭션이 커밋되지 않았다 하더라도 em.persist에 의해서 영속성 컨텍스트의 1차 캐시에 entity가 저장되었을건데, 왜 em.find로 찾지 못한 것일까??
그건 바로 Transaction에 따른 persistence context 때문이다. persistence context는 각 Transaction별로 생성된다
이 말은, 부모 트랜잭션에서 사용하는 영속성 컨텍스트와 자식 트랜잭션에서 사용하는 영속성 컨텍스트가 다르다는 것을 의미한다. 따라서 부모 트랜잭션에서 save(entity)로 1차캐시에 저장한 엔티티를, 자식 트랜잭션에서 em.find(entity)로 암만 찾아봐도 찾을 수가 없다는 것이다..

나는 부모 트랜잭션에서 save(entity)를 한 이후, 쿼리도 날라가고 entity.getId() 로그 또한 잘 나오길래 아무런 문제가 없을 줄 알았는데, 두 트랜잭션은 부모 트랜잭션이 커밋되기 전까지 소통을 하고 싶어도 할 수 없는 상황인 것이다..
어라..? 그런데 여기서 이상한 점이 있다. 쿼리가 날라가고 id가 잘 나온다고..?

Id 생성 전략을 IDENTITY로 설정했기 때문에, DB에 id 생성을 전적으로 위임하였고, DB에 접근하지 않았다면 Id가 null이어야 할텐데..? 그리고 쿼리 또한 commit이 이루어져야 날라갈텐데 어떻게 된 일일까??
GeneratedValue = IDENTITY에서는 em.commit이 발생하기 전에 em.flush가 일어난다
이는 GeneratedValue = IDENTITY 동작 방식 때문이다.
위에서 말했듯이 IDENTITY 전략을 사용하면 id 생성을 전적으로 DB에 위임하기 때문에, save를 호출하면 persist()로 객체를 영속화 시키는 시점에 곧바로 insert 쿼리를 DB로 날려서 id를 생성한다.
즉, save를 호출하면 트랜잭션 커밋과 상관없이 db에 저장이 된다는 뜻이다..!!
그렇다면 문제는 다시 원점으로 돌아가게 된다.
도대체 왜 자식 트랜잭션에서 부모 트랜잭션에서 저장한 엔티티가 조회가 안될까??????????????????????
도대체 왜 자식 트랜잭션에서 부모 트랜잭션에서 저장한 엔티티가 조회가 안될까??????????????????????
도대체 왜 자식 트랜잭션에서 부모 트랜잭션에서 저장한 엔티티가 조회가 안될까??????????????????????
Isolation Level로 최종 원인 찾기
하루종일 고민하느라 멘탈도 깨지고, 도저히 혼자 힘으로는 벅차다 생각해서 개발바닥 2사로 선배님들에게 도움을 요청했다
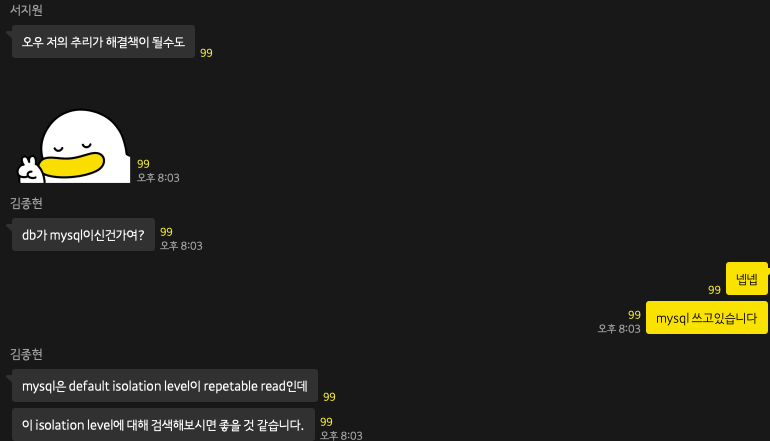
지원님께서 먼저 isolation level을 언급해주셨고, 종현님께서 추가적으로 자세한 설명을 주셨다. (도움 주신 종현님 지원님 감사합니다!! )
mysql에서는 isolation level이 repetable read이기 때문에, 트랜잭션이 커밋되기 전까지는 변경 사항이 다른 트랜잭션에 보이지 않는다는것..!
결국 isolation level을 조정해야 하나 싶었지만 종현님께서 mysql은 transaction isolation level을 강제로 repetable read로 해놨기 때문에 조정할 수 없다고 하셨다..
그렇다면 정말 방법이 없는걸까?
최종 해결 방안
두 가지 방법이 생각났다.
첫 번째는 위에서 언급한것처럼 Spring Event를 사용해서 처리하는 것이다. 그리고 두 번째는 부모 트랜잭션에서 저장한 entity를 자식 트랜잭션에서 사용하지 않는 것이다.
물론 나는 당연히 두 번째 방법을 사용했다. 이유는.. 위에서 언급했으니 생략하도록 하겠다.
먼저 Pet과 UserInterestList에서 User 엔티티와의 연관 관계를 모두 끊어냈다. 연관 관계를 끊을 때를 대비해서 이미 User의 UUID를 컬럼으로 추가해뒀기 때문에 User 엔티티만 덜어내면 되는 작업이었다.
물론 연관관계가 끊어졌기에 정합성을 잘 관리해야겠지만.. 언젠가는 해야 할 일을 당겨서 했다고 생각해야겠다
코드




잘가라 지긋지긋한 User..!!
Reference
Transaction silently rolled back because it has been marked as rollback-only
이게 왜 저장이 안될까? 서비스를 운영하다가 이 포스팅의 제목과 같이 Transaction silently rolled back because it has been marked as rollback-only 라는 에러 메시지를 받게 되었습니다. 해당 에러의 원인은 금방
keencho.github.io
- Requires_new에 대한 오해: https://woodcock.tistory.com/40
Transactional REQUIRES_NEW에 대한 오해
서론예전에 함께 스터디를 했던 스터디원이 트랜잭션에 관한 블로그 글을 공유하면서, 흥미로운 내용이라고 소개했다.해당 글에서는 기존에 내가 알고있던 사실이 틀리다라고 얘기하는 내용이
woodcock.tistory.com
- 스프링 트랜잭션 REQUIRES_NEW: https://m.blog.naver.com/fbfbf1/223058315795
스프링 트랜잭션 REQUIRES_NEW
트랜잭션 복구 Service A에서 RepositoryB와 Repository C를 호출한다고 가정해 보자. Repository ...
blog.naver.com
- JPA 기본키 생성 전략: https://devcamus.tistory.com/16
JPA 기본키 생성 전략, @GeneratedValue 사용시 주의점
JPA로 테이블과 엔티티를 매핑할 때, 식별자로 사용할 필드 위에 @Id 어노테이션을 붙여 테이블의 Primary Key와 연결 시켜줘야한다. 이 때, 컬럼 명을 따로 지정하지 않으면, 관례에 따라 매핑되는
devcamus.tistory.com