현재 Untitled의 유저 쇼츠 테이블을 보면, 특정 쇼츠를 조회를 위해 '쇼츠 좋아요 수'가 필요하기 때문에 매번 count 쿼리를 날려야 한다.
또한 단순 쇼츠 조회뿐만 아니라 인기순으로 정렬을 할 때도 '쇼츠 좋아요 수' 가 필요했는데, 이 기능은 '쇼츠 좋아요 수'를 count 하여 정렬하고 page size만큼 shorts를 가져오는 로직이다.
따라서 이러한 구조는 유저가 늘어나면 분명히 성능에 악영향을 끼치리라 판단하여 리팩토링을 시작하게 됐다

Count Query
먼저 가장 큰 영향을 주는 건 count 쿼리라고 생각해서, 이 부분을 없애기로 했다.
그래서 구조 자체를 수정해야 했고, 테이블에 '좋아요 수'를 컬럼으로 저장하기로 했다. 이런 구조에서는 곧바로 '좋아요 수'를 불러올 수 있기에 count 쿼리를 사용하지 않아도 된다!!
문제 해결!! 끗!!
끗..! 이면 좋겠지만.. 여기서 문제는 "유저가 좋아요를 누르거나 취소할 때마다 UserShorts 테이블과 ShortsLike 테이블에 계속 쿼리를 날려줘야 하는것인가?" 였다.
만약 요청 시마다 쿼리를 날려준다면 DB connection이 너무 많아져서 유저 몇 명만 좋아요/좋아요 취소를 누르더라도 거의 디도스 공격이나 마찬가지가 될 것이다.
그럼 어떻게 할까?
Spring Cache
캐시를 사용하면 된다! 먼저 캐싱을 사용할 때와 사용하지 않을 때의 플로우를 보자
캐싱을 사용하지 않는 경우 플로우
- 유저의 id로 ShortsLike 테이블을 조회
-> 존재한다면 좋아요를 눌렀던 상황이므로, 이번 Request로 인해 좋아요를 삭제해야 함 - 좋아요 여부에 따라 다음 과정을 수행
a-1. 좋아요가 존재한다면 ShortsLike를 삭제
a-2. DB에서 shortsLikeCount를 -1 해준다
b-1. 좋아요가 없다면 ShortsLike를 생성
b-2. DB에서 shortsLikeCount를 +1 해준다
: 이 경우 매번 좋아요 이벤트 발생시마다 ShortsLike 테이블과 UserShorts 테이블에 쿼리를 날려줘야 하므로 2*N번의 쿼리가 발생한다
캐싱을 사용하는 플로우
: 좋아요를 누르거나 취소할 때는 DB에 곧바로 접근하지 않고, Scheduler를 통해서 주기적으로 동기화시키므로 DB connection을 줄일 수 있다.
: '좋아요 수' 를 조회할 때는 Cache에서 해당 쇼츠에 대한 캐싱 정보가 있는지 확인 후 바로 return 해준다. 만약 정보가 없다면 DB에서 꺼내온 후 그 값을 client에 전해주고 Cache에 값을 저장한다. 따라서 최초 조회 시 딱 한 번만 DB connection이 일어나게 된다.
- 유저의 id로 ShortsLike 테이블을 조회
-> 존재한다면 좋아요를 눌렀던 상황이므로, 이번 Request로 인해 좋아요를 삭제해야 함 - 좋아요 여부에 따라 다음 과정을 수행
a-1. 좋아요가 존재한다면 ShortsLike를 삭제
a-2. 캐시에서 해당 게시글의 shortsLikeCount를 -1 해준다
b-1. 좋아요가 없다면 ShortsLike를 생성
b-2. 캐시에서 해당 게시글의 shortsLikeCount를 +1 해준다 - Spring Scheduler를 통해서, 5분에 한 번씩 Cache의 shortsLikeCount 값과 DB의 ShortsLikeCount 값을 동기화시켜 준다
: 이 경우 아무리 많은 좋아요 이벤트가 발생하더라도, UserShorts 테이블에는 5분에 한 번씩만 쿼리가 날아가므로 N+M번의 쿼리만 발생한다 (여기서 M은 좋아요 Count를 업데이트 시켜줄 쇼츠 개수)
물론 5분에 한 번씩 Cache에 저장된 모든 쇼츠에 대해서 업데이트 쿼리를 날려줘야 하지만, 사용할 때와 사용하지 않을 때를 비교하면 굉장한 차이가 있다.
5분 동안 각 쇼츠에 분당 10번의 좋아요 이벤트가 발생했다고 생각해 보자. 이벤트가 발생한 쇼츠가 총 10개라 가정하고 UserShorts 테이블과 ShortsLikeCount 테이블에 발생하는 쿼리 수를 계산해 보면,
- 캐싱을 사용하지 않는 경우
총 쿼리 호출 수 = 2N*S = 2*50*10 = 1000 번의 쿼리가 발생 - 캐싱 처리를 한 경우
총 쿼리 호출 수 = N*S + M = 50*10 + 10 = 510 번의 쿼리가 발생
(* N = 5분동안 좋아요 API 호출 수, M = 좋아요 Count를 업데이트 시켜줄 쇼츠 수, S = 좋아요 이벤트가 발생한 쇼츠 수)
차이가 보이는가? 거의 두 배의 쿼리 차이가 발생하는 것을 알 수 있다
구현
그럼 이제 어떻게 구현했는지 코드로 확인해 보자
변경 전
기존 코드를 보면 알 수 있듯이 단순히 ShortsLike 테이블을 생성/삭제만을 반복하고, '좋아요 수'가 필요한 부분에서는 count 쿼리를 사용해서 조회하고 있다
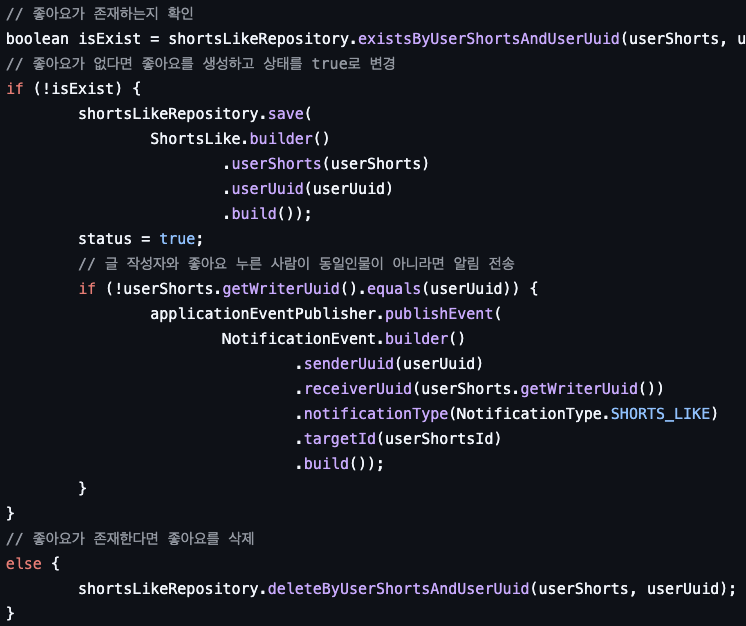
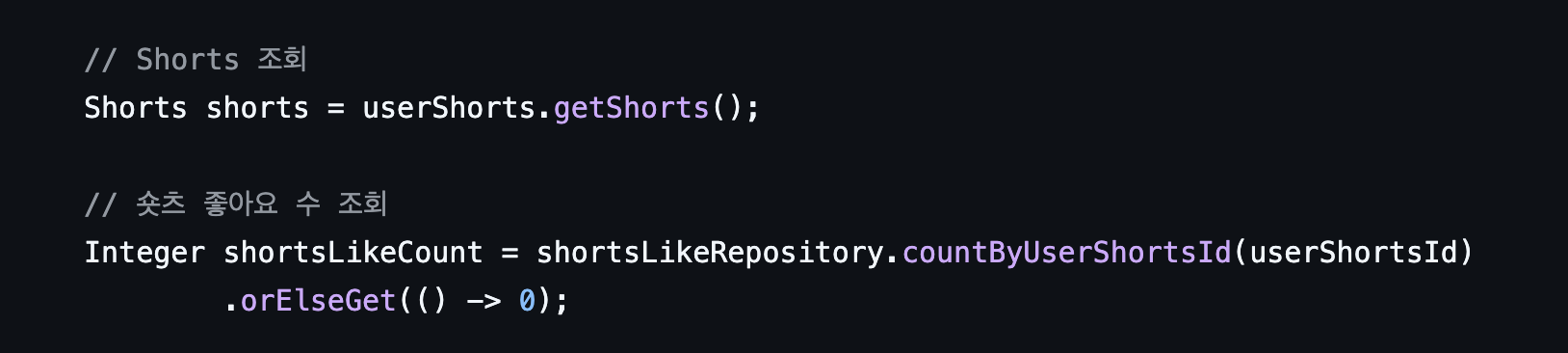
변경 후
Spring Cache를 사용하여 '좋아요 수' 조회, 업데이트를 캐싱 처리 하였다. 이때 사용한 Cache 저장소는 기존 서비스에서 사용 중이던 Redis를 사용하기로 했다.
1. RedisConfig
먼저 Redis를 사용해야 하므로 설정을 해주자
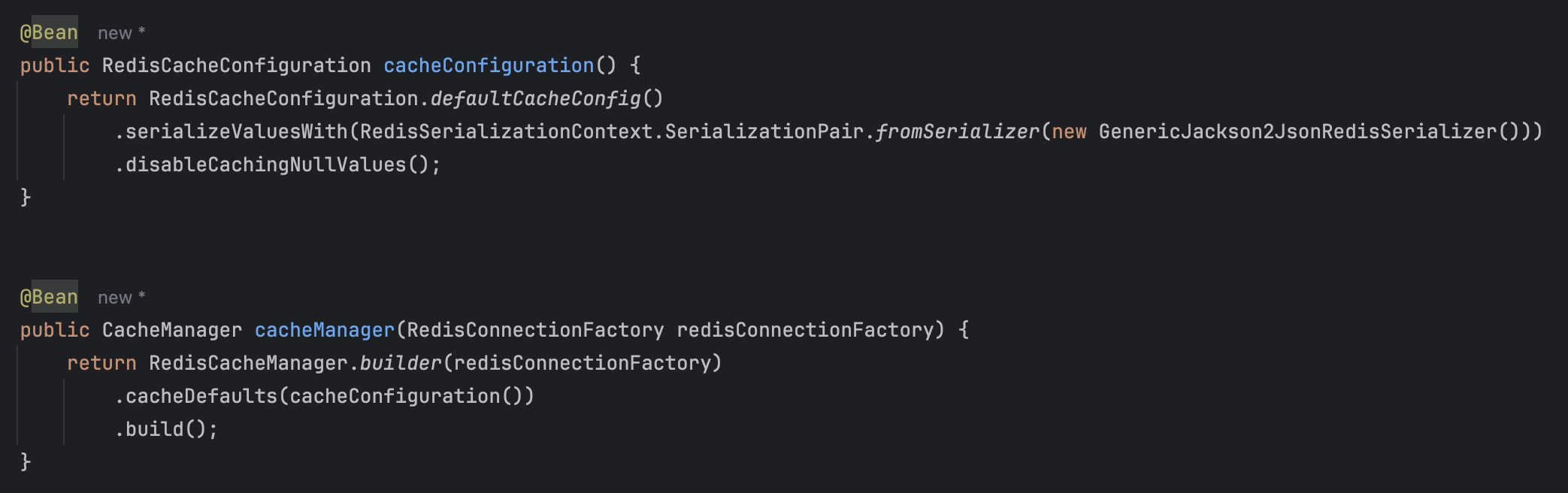
- cacheConfiguration(): 캐싱에서 사용할 직렬화/역직렬화 등을 설정한다
- cacheManager(): SpringCache에서 방금 설정한 cacheConfiguration을 사용하도록 설정한다
2. RedisUtil
다음으로 redis에서 값을 증가/감소 시키는 메서드와 특정 패턴으로 시작되는 key:value를 가져오는 메서드를 작성하자
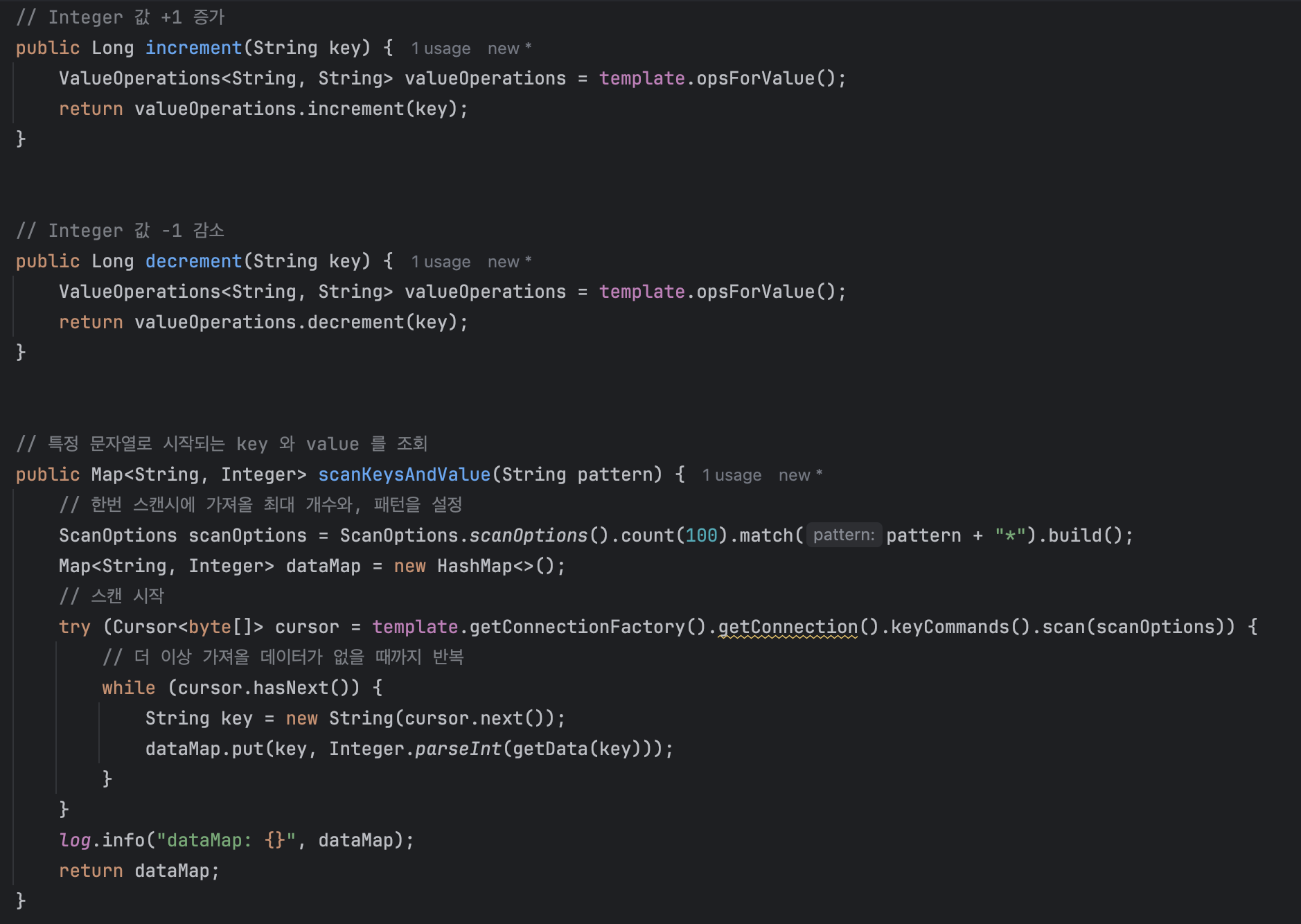
- 여기서 중요한 건 template.getKeys()가 아니라 scan을 쓴 부분이다. keys는 해당하는 모든 key를 조회하므로, 싱글 스레드로 동작하는 redis 특성상 key가 많아지면 blocked 되는 시간이 길어지므로 redis를 사용하는 다른 로직에 좋지 않은 영향을 미친다
- 따라서 특정 개수만큼 가져와주는 scan을 사용해서 최대한 block 되는 시간을 줄여주자
3. Cache Service
SpringCache는 프록시 기반으로 작동하기 때문에, 같은 클래스 안에서 정의하면 호출할 수가 없다. 따라서 캐싱 메서드만 따로 정의하는 CacheService를 만들어서 사용해야 한다

- 조회 메서드에서는 @Cacheable을 사용한다
- @Cacheable: 캐시 저장소에서 "value::key"에 해당하는 key로 조회 후, 값이 존재한다면 그대로 return. 값이 없다면 메서드에 정의된 return값을 반환 후, 캐시에 저장해 준다
- 위 메서드에서는 redis에 "shortsLikeCount::294" 와 같은 형태로 저장된다

- 업데이트 메서드에서는 @CachePut을 사용한다
- @CachePut: 캐시에서 key에 해당하는 값에 return 값을 설정한다. 업데이트해주는 개념이 아니라 그냥 강제로 집어넣는 개념이기 때문에, 아까 RedisUtil에서 정의한 increment와 decrement를 사용해 준다.
- increment와 decrement는 redis에서 기본적으로 제공해 주는 메서드로, key에 해당하는 value를 가져온 후 +1, -1 해주는 메서드다

- 마지막으로 동기화 부분이다
- shortsLikeCount에 해당하는 "key:value" 들을 redis에서 모두 찾아온 후, 순차적으로 돌아가며 DB에 update 시킨다
위의 코드를 잘 응용해서 자신의 서비스에 알맞게 적용해 보길 바란다!!
** 블로그에 작성된 글에는 잘못된 정보가 있을 수 있습니다. 피드백은 언제나 환영입니다.
Referecne
- Spring Scheduler로 조회수 로직 캐싱 구현하기 (feat. Redis): https://velog.io/@bagt/Spring-Scheduler%EB%A1%9C-%EC%A1%B0%ED%9A%8C%EC%88%98-%EB%A1%9C%EC%A7%81-%EC%BA%90%EC%8B%B1-%EA%B5%AC%ED%98%84%ED%95%98%EA%B8%B0
[Project] Spring Scheduler로 조회수 로직 캐싱 구현하기 (feat. Redis)
이전 포스팅 >Spring Cache 적용으로 읽기 성능 최적화하기 (2) 이번엔 게시글에 대한 캐싱이다. 게시글 캐싱의 경우 마이페이지에 비해 고려해야할 사항이 많았다. 조회수 증가 좋아요 추가 이 두가
velog.io